Building a Kubernetes platform at Pinterest

The real life case study
Building a Kubernetes platform at Pinterest
Over the years, 300 million Pinners have saved more than 200 billion Pins on Pinterest across more than 4 billion boards. To serve this vast user base and content pool, we’ve developed thousands of services, ranging from microservices of a handful CPUs to huge monolithic services that occupy a whole VM fleet. There are also various kinds of batch jobs from all kinds of different frameworks, which can be CPU, memory or I/O intensive.
Why Kubernetes?
To support these diverse workloads, the infrastructure team at Pinterest is facing multiple challenges:
- Engineers don’t have a unified experience when launching their workload. Stateless services, stateful services and batch jobs are deployed and managed by totally different tech stacks. This has created a steep learning curve for our engineers, as well as huge maintenance and customer support burdens for the infrastructure team.
- Engineers managing their own VM fleets is creating a huge maintenance load for the infra team. Simple operations such as an OS or AMI upgrade can take weeks to months. Production workloads are also disturbed during those processes, which are supposed to be transparent to them.
- It’s hard to build infrastructure governance tools on top of separated management systems. It’s even more difficult for us to determine who owns which machines and if they can be safely recycled.
Container orchestration systems provide a way to unify workload management. They also pave the way to faster developer velocity and easier infra governance since a centralized system manages all running resources.
he Cloud Management Platform team at Pinterest started their journey on Kubernetes back in 2017. We dockerized most of our production workloads, including the core API and Web fleets, by the first half of 2017. Extensive evaluation on different container orchestration systems was then done by building prod clusters and operating real workloads on them. By the end of 2017, we decided to go down the path of Kubernetes because of its flexibility and extensive community support.
So far, we’ve built our own cluster bootstrap tools based on Kops and integrated existing infrastructure components into our Kubernetes cluster, such as network, security, metrics, logging, identity management and traffic. We introduced Pinterest-specific custom resources to model our unique workloads while hiding the runtime complexity from developers. We’re now focusing on cluster stability, scalability, and customer onboarding.

Figure 1: Infrastructure priorities (Service Reliability, Developer Productivity, and Infra Efficiency)
Kubernetes, the Pinterest way
Running Kubernetes to support workloads at Pinterest scale, while also making it a platform loved by our engineers, has many challenges.
As a large organization, we have invested heavily in infrastructure tools, such as security tools that handle certificates and key distribution, traffic components that enable service registration and discovery, and visibility components that ship logs and metrics. These are components built on lessons learned the hard way, so we want to integrate them into Kubernetes instead of reinventing the wheel. This also makes migration much easier, as the required support is already there for our internal applications.
On the other hand, the Kubernetes native workload model, such as deployment, jobs and daemonsets, are not enough for modeling our own workloads. Usability issues are huge blockers on the way to adopt Kubernetes. For example, we’ve heard service developers complaining about missing or misconfigured ingress messing up their endpoints. We’ve also seen batch job users using template tools to generate hundreds of copies of the same job specification and ending up with a debugging nightmare.
Runtime support for the workloads is also evolving, so it would be extremely hard to support different versions on the same Kubernetes cluster. Just imagine the complexity of customer support if we needed to face many versions of the runtime, together with the difficulties of upgrading or bug-patching for them.
Pinterest custom resources and controllers
In order to pave an easier way for our engineers to adopt Kubernetes and make infra development faster and smoother, we designed our own Custom Resource Definitions (CRDs).
The CRDs provide the following functionalities:
- Bundle various native Kubernetes resources together so they work as a single workload. For example, the PinterestService resource puts together a deployment, a service, an ingress and a configmap, so service developer will not need to worry about setting up DNS for their service.
- Inject necessary runtime support for the applications. The user only needs to focus on the container spec for their own business logic, while the CRD controller injects necessary sidecars, init containers, environment variables and volumes into their pod spec. This provides an out-of-box experience to the application engineers.
- CRD controllers also do life cycle management for the native resources and handle visibility and debuggability. This includes but is not limited to reconciling the desired spec and the actual spec, CRD status updating and event recording. Without CRDs, app engineers must manage a much larger set of resources, and this process has proved to be error prone.
Here’s an example of PinterestService and the native resource translated by our controller:

Figure 2: CRD to native resources. The left is the Pinterest CR written by user, and the right is the native resource definition generated by the controller.
As shown, to support a user’s container, we need to insert an init container and several sidecars for security, visibility and network traffic. Additionally, we introduced configuration map templates and PVC template support on batch jobs, as well as many environment variables to track identity, resource utilization, and garbage collection.
It’s hard to imagine engineers would be willing to hand-write these configuration files without CRD support, let alone maintain and debug the configurations.
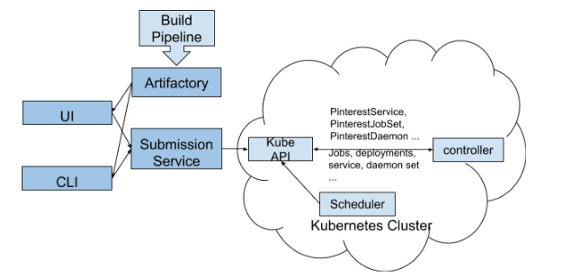
Figure 3: Pinterest CRD Overview
Application Deploy Workflow
Figure 3 shows how to deploy a Pinterest custom resource to the Kubernetes cluster:
- Developers interact with our Kubernetes cluster via CLI and UI.
- The CLI/UI tools retrieve workflow configuration YAML files and other build properties (such as version ID) from Artifactory and send them to the Job Submission Service. This ensures only reviewed and landed workloads will be submitted to the Kubernetes cluster.
- The Job Submission service is the gateway to various computing platforms, including Kubernetes. User authentication, quota enforcement and partial Pinterest CRD configuration validation happens here.
- Once the CRD passes the Job Submission service validation, it’s sent to the Kubernetes API.
- Our CRD controller watches events on all custom resources. It transforms the CR into Kubernetes native resources, adds necessary sidecars into user defined pods, sets appropriate environment variables and does other necessary housekeeping work to ensure the user’s application containers have enough infrastructure support.
- The CRD controller then writes the resulting native resources back to the Kubernetes API so they can be picked up by the scheduler and start to run.
Note: This is the pre-release deploy workflow used by early adopters of the new Kubernetes-based Compute Platform. We are in the process of revamping this experience to be fully integrated with our new CI/CD platform to avoid exposing a lot of Kubernetes-specific details. We look forward to sharing the motivation, progress and subsequent impact in an upcoming blog post — “Building a CI/CD platform for Pinterest.”
Custom Resource Types
Based on Pinterest’s specific needs, we designed the following CRDs that suit different workflows:
- PinterestService is the long running stateless service. Many core systems are based on a set of such services.
- PinterestJobSet models the batch jobs that run to completion. A very common pattern within Pinterest is that multiple jobs runs the same containers in parallel, each grabbing a fraction of a workload without depending on each other.
- PinterestCronJob is widely adopted by teams with lightweight periodic workloads. PinterestCronJob is a wrapper around the native cron job, with Pinterest-specific support such as security, traffic, log and metrics.
- PinterestDaemon is limited to the infrastructure-related daemons. The family of PinterestDaemon is still growing as we are adding more support on our clusters.
- PinterestTrainingJob wraps around Tensorflow and Pytorch jobs, providing the same level of runtime support as all other CRDs. Since Pinterest is a heavy user of Tensorflow and other machine learning frameworks, it makes sense to build a dedicated CRD around them.
We also have PinterestStatefulSet under construction, which will soon be adopted for storage and other stateful systems.
Runtime Support
When an application pod starts on Kubernetes, it automatically gets a certificate to identify itself. This cert is used to access the secrets store or talk to other services via mTLS. Meanwhile, the config management init containers and daemon will ensure all necessary dependencies downloaded before the application container starts. When the application container is ready, the traffic sidecar and daemon will register the pod IP to our Zookeeper in order to make it discoverable by clients. Networking has been set up for the pod by network daemon before the pod even starts.
The above are examples of typical runtime support for service workloads. Other workload types may need slightly different support, but they all come in the form of pod-level sidecars, node-level daemonsets or VM-level daemons. We make sure all of them are deployed by the infrastructure team so they are consistent between all applications, which greatly reduces the maintenance and customer support burden for us.
Testing and QA
We built an end-to-end test pipeline on top of the native Kubernetes test infra. These tests are deployed to all clusters. This pipeline has caught many regression before they reach the production cluster.
Besides the testing infra, there is also monitoring and alerting systems that watch the system components’ health status, resource utilization and other critical metrics consistently, notifying us when human intervention is needed.
Alternatives
We considered some alternatives to custom resources, such as mutation admission controllers and templating systems. However, the alternatives all come with major issues, so we chose the path of CRDs.
- Mutating admission controller has been used to inject sidecars, environment variables and other runtime support. However, it has difficulties bundling resources together as well as managing their life cycle, whereas CRD comes with reconciling, status update and lifecycle management.
- Templating systems such as Helm charts are also widely used to launch applications with similar configurations. However, our workloads are too diverse to be managed by templates. We also need to support continuous deployment, which would be extremely error prone with templates.
Future Work
Currently, we are running mixed workloads on all of our Kubernetes clusters. In order to support workloads of different sizes and types, we are working on the following areas:
- Cluster Federation spreads large applications over different clusters for scalability and stability.
- Cluster Stability, Scalability and Visibility that makes sure applications reach their SLA.
- Resource and Quota Management to make sure applications do not step on each other’s feet and the cluster scale is under control.
- New CI/CD Platform to support Application Deployment on Kubernetes
Acknowledgements
Many engineers at Pinterest helped build the platform from the ground up. Micheal Benedict and Yongwen Xu, who lead our engineering productivity effort, have worked together on setting the direction of the compute platform, discussing the design and helping with feature prioritization from the very beginning. Jasmine Qin and Kaynan Lalone helped on the Jenkins and Artifactory integration support. Fuyuan Bie, Brain Overstreet, Wei Zhu, Ambud Sharma, Yu Yang, Jeremy Karch, Jayme Cox, and many others helped build the config management, metrics, logging, security, networking and other infra support. Jooseong Kim and George Wu helped build the Submission Service. Lastly, our early adopters Prasun Ghosh, Michael Permana, Jinfeng Zhuang and Ashish Singh provided a lot of useful feedback and feature requirements.
By Lida Li, June Liu, Rodrigo Menezes, Suli Xu, Harry Zhang, Roberto Rodriguez Alcala | Pinterest Software Engineers, Cloud Management Platform
This post was originally posted on the Stackhare https://stackshare.io/pinterest/building-a-kubernetes-platform-at-pinterest